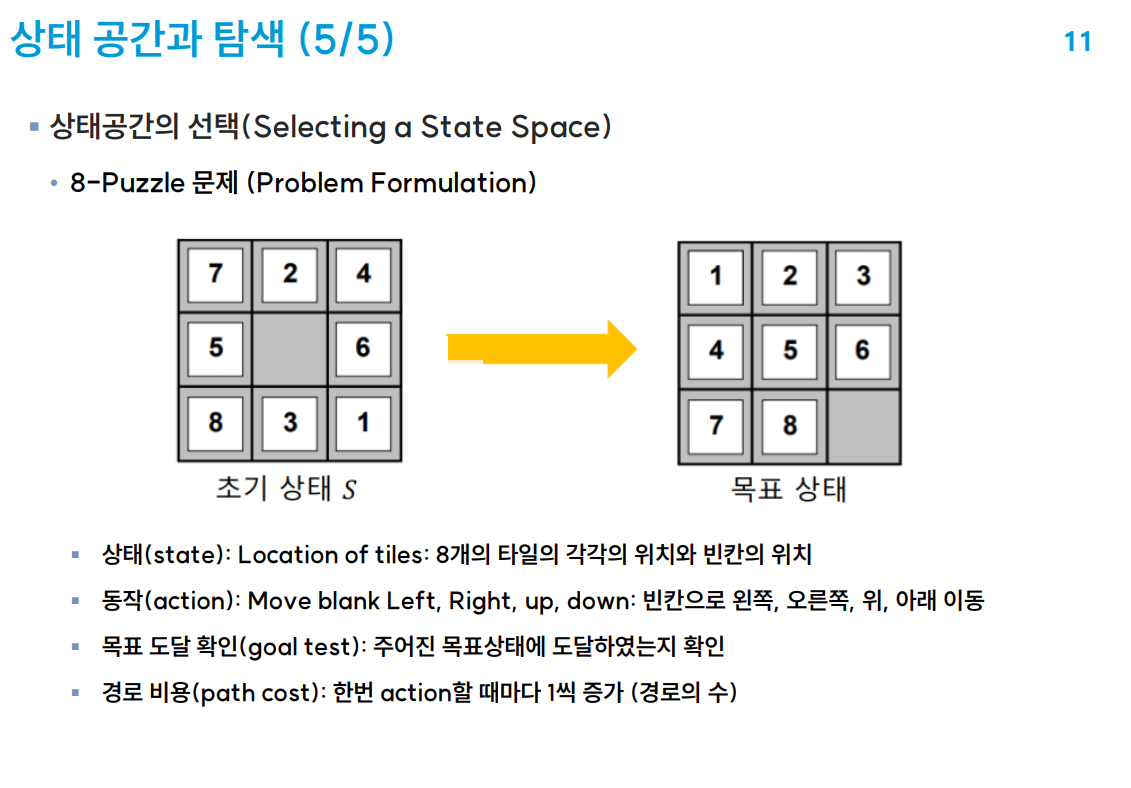
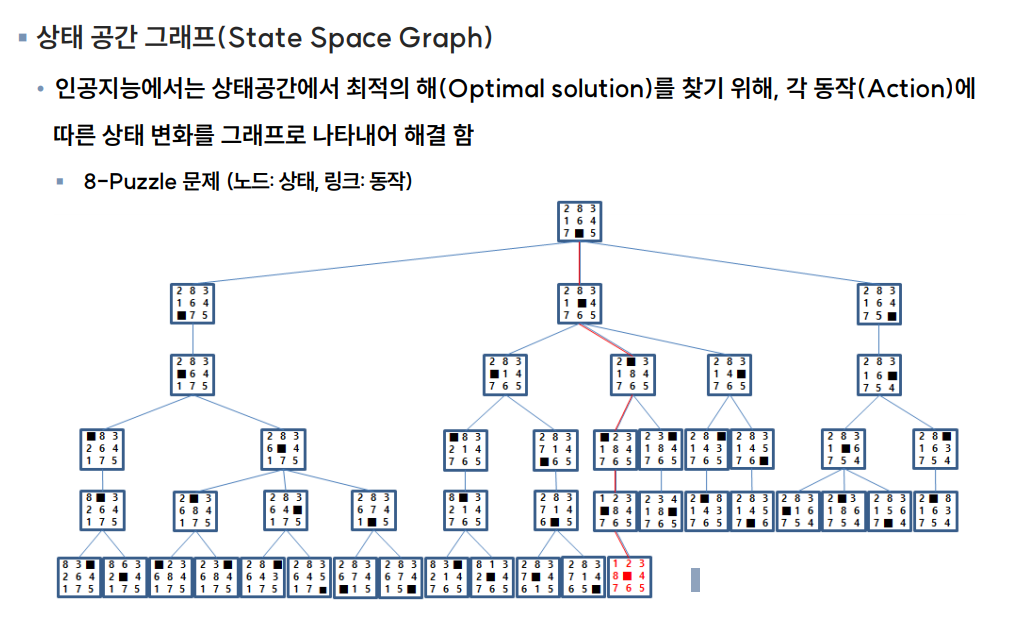
퍼즐 맞추기인데
교수님이 억까 코드로 실습하라고 했음...
그래서 일단 억까코드 수정하고 저렇게 만들어봤는데
bfs는 교수님 원본 코드에서 딱히 바뀐건 없고
주석이랑 조건문 위치랑 moves 프린트 수정했고
dfs는 실습이었는데
저렇게 만드는게 맞나 모르겠다..
일단 무한적으로 탐색하던건 조건문 위치랑 조건 수정해서 고쳐졌고
set으로 중복체킹하는데 시간복잡도 O(1)로 수정함

BFS
class State:
def __init__(self, board, goal, moves=0):
self.board = board
self.moves = moves
self.goal = goal
# i1과 i2를 교환하여서 새로운 상태를 반환한다.
def get_new_board(self, i1, i2, moves):
new_board = self.board[:]
new_board[i1], new_board[i2] = new_board[i2], new_board[i1]
return State(new_board, self.goal, moves)
def expand(self, moves):
result = []
i = self.board.index(0) # 숫자 0(빈칸)의 위치를 찾는다.
if not i in [0, 1, 2]: # UP 연산자
result.append(self.get_new_board(i, i - 3, moves))
if not i in [0, 3, 6]: # LEFT 연산자
result.append(self.get_new_board(i, i - 1, moves))
if not i in [2, 5, 8]: # DOWN 연산자 -> 사실 RIGHT 연산자로 추정
result.append(self.get_new_board(i, i + 1, moves))
if not i in [6, 7, 8]: # RIGHT 연산자 -> 사실 DOWN 연산자로 추정
result.append(self.get_new_board(i, i + 3, moves))
return result
# 객체를 출력할 때 사용한다.
def __str__(self):
return str(self.board[:3]) + "\n" + \
str(self.board[3:6]) + "\n" + \
str(self.board[6:]) + "\n" + \
"------------------"
def __eq__(self, other):
return self.board == other.board
if __name__ == "__main__":
puzzle = [2, 8, 3,
1, 6, 4,
7, 0, 5]
goal = [1, 2, 3,
8, 0, 4,
7, 6, 5]
# open 리스트
not_visited = [State(puzzle, goal)]
visited = []
moves = 0
while not_visited: # 스택이 빌 때까지
current = not_visited.pop(0) # 방문하려는 노드를 not_visited에서 삭제
print(current, current.moves)
if current.board == goal:
print("탐색 성공")
break
if current not in visited:
visited.append(current)
moves = current.moves + 1
for state in current.expand(moves):
if state in visited: # 이미 거쳐간 노드이면
continue # 노드를 버린다.
else:
not_visited.append(state) # 리스트 추가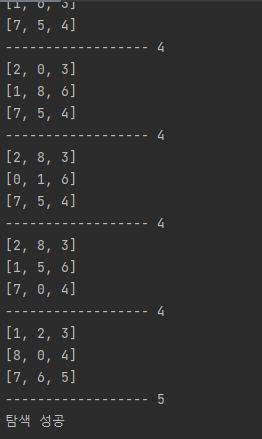
DFS
class State:
def __init__(self, board, goal, moves=0):
self.board = board
self.moves = moves
self.goal = goal
# i1과 i2를 교환하여서 새로운 상태를 반환한다.
def get_new_board(self, i1, i2, moves):
new_board = self.board[:]
new_board[i1], new_board[i2] = new_board[i2], new_board[i1]
return State(new_board, self.goal, moves)
def expand(self, moves):
result = []
i = self.board.index(0) # 숫자 0(빈칸)의 위치를 찾는다.
if not i in [0, 1, 2]: # UP 연산자
result.append(self.get_new_board(i, i - 3, moves))
if not i in [0, 3, 6]: # LEFT 연산자
result.append(self.get_new_board(i, i - 1, moves))
if not i in [2, 5, 8]: # DOWN 연산자 -> 사실 RIGHT 연산자로 추정
result.append(self.get_new_board(i, i + 1, moves))
if not i in [6, 7, 8]: # RIGHT 연산자 -> 사실 DOWN 연산자로 추정
result.append(self.get_new_board(i, i + 3, moves))
return result
# 객체를 출력할 때 사용한다.
def __str__(self):
return str(self.board[:3]) + "\n" + \
str(self.board[3:6]) + "\n" + \
str(self.board[6:]) + "\n" + \
"------------------"
def __eq__(self, other):
return self.board == other.board
def __hash__(self):
return hash((tuple(self.board)))
if __name__ == "__main__":
puzzle = [2, 8, 3,
1, 6, 4,
7, 0, 5]
goal = [1, 2, 3,
8, 0, 4,
7, 6, 5]
# open 리스트
not_visited = [State(puzzle, goal)]
visited_set = set()
moves = 0
while not_visited: # 스택이 빌 때까지
current = not_visited.pop() # 방문하려는 노드를 not_visited에서 삭제
print(current, current.moves)
if current.board == goal:
print("탐색 성공")
break
if current not in visited_set:
visited_set.add(current)
moves = current.moves + 1
for state in current.expand(moves):
if state not in visited_set: # 이미 거쳐간 노드가 아니면
not_visited.append(state) # 리스트 추가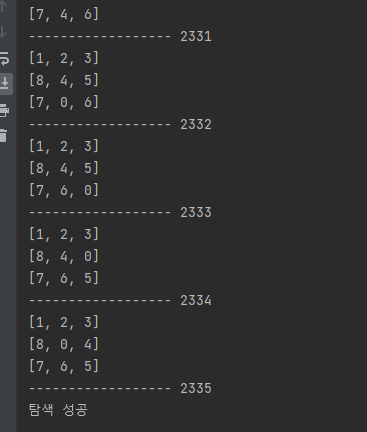
DFS는 노드간의 간선을 미리 설정해놓지 않는 무정보탐색에서는
이렇게 정말 많은 반복을 하는것같음
그래서 dfs는 set 클래스로 시간복잡도를 개선했는데
뭔 2천번 넘게 탐색을해서 저렇게 수정하는게 맞나 모르겠음
암튼 bfs도 set 클래스를 써도 되는데 코드 차이를 보라고 저렇게 해봤음
Best-First Search (그리디 알고리즘) + a* 알고리즘
class State:
def __init__(self, board, goal, moves=0):
self.board = board
self.moves = moves
self.goal = goal
# i1과 i2를 교환하여서 새로운 상태를 반환한다.
def get_new_board(self, i1, i2, moves):
new_board = self.board[:]
new_board[i1], new_board[i2] = new_board[i2], new_board[i1]
return State(new_board, self.goal, moves)
def expand(self, moves):
result = []
i = self.board.index(0) # 숫자 0(빈칸)의 위치를 찾는다.
if not i in [0, 1, 2]: # UP 연산자
result.append(self.get_new_board(i, i - 3, moves))
if not i in [0, 3, 6]: # LEFT 연산자
result.append(self.get_new_board(i, i - 1, moves))
if not i in [2, 5, 8]: # DOWN 연산자 -> 사실 RIGHT 연산자로 추정
result.append(self.get_new_board(i, i + 1, moves))
if not i in [6, 7, 8]: # RIGHT 연산자 -> 사실 DOWN 연산자로 추정
result.append(self.get_new_board(i, i + 3, moves))
return result
# 객체를 출력할 때 사용한다.
def __str__(self):
return str(self.board[:3]) + "\n" + \
str(self.board[3:6]) + "\n" + \
str(self.board[6:]) + "\n" + \
"------------------"
def __eq__(self, other):
return self.board == other.board
def __hash__(self):
return hash((tuple(self.board)))
def f(self):
return self.g() + self.h()
def g(self):
return self.moves
def h(self):
return sum([1 if self.board[i] != self.goal[i] else 0 for i in range(8)])
def __lt__(self, other):
return self.f() < other.f()
puzzle = [2, 8, 3,
1, 6, 4,
7, 0, 5]
goal = [1, 2, 3,
8, 0, 4,
7, 6, 5]
# open 리스트
not_visited = [State(puzzle, goal)]
visited_set = set()
moves = 0
while not_visited: # 스택이 빌 때까지
current = min(not_visited) # 가장 휴리스틱 값이 최적인 것을 현재 노드로 선택
not_visited.remove(current)
print(current, current.moves)
if current.board == goal:
print("탐색 성공")
break
if current not in visited_set:
visited_set.add(current)
moves = current.moves + 1
for state in current.expand(moves):
if state not in visited_set: # 이미 거쳐간 노드가 아니면
state.f_value = state.f()
not_visited.append(state) # 리스트 추가
휴리스틱 값을 퍼즐이 골의 퍼즐과 다른 상태를 h() 시작 노드에서 현재 노드까지 거리를 g() 으로 합쳐서
최선탐색 알고리즘과 a스타 알고리즘으로 작성했다 그런데 정확하게 아직은 모르겠다
아직 가장 최적으로 찾는게 없어서 나중에 수정해야한다
'정리 전 게시글 > 공부 관련' 카테고리의 다른 글
| [백준 1152번 문제, C] 단어의 개수 (0) | 2023.04.02 |
|---|---|
| [백준 1969번 문제, Python3] DNA (0) | 2023.03.29 |
| [백준 1485번 문제, Python3] 정사각형 (0) | 2023.03.25 |
| 자바 양방향 그래프 dfs - 2차원 행렬, 반복문, 스택, LinkedHashSet (0) | 2023.03.21 |
| 운영체제 (1) ~ (3) 주차 학습 노트 (0) | 2023.03.20 |