파이썬 웹 크롤링 공부를 하면서 슬랙이라는 플랫폼을 알게되었고 파이썬으로 챗봇을 만들 수 있다는 것을 알게되었다.
이번에 파이썬으로 챗봇을 만들고 채팅오게 하는 방법을 써보려고 한다.
1. Slack 슬랙 회원가입 및 로그인
클라우드 기반의 비즈니스 커뮤니케이션 플랫폼
워크스페이스에서 팀원들과 협업이 가능하고 파일 및 공유가 가능하며 화상 회의도 가능하다
Slack은 생산성 플랫폼입니다
Slack은 팀과 커뮤니케이션할 수 있는 새로운 방법입니다. 이메일보다 빠르고, 더 조직적이며, 훨씬 안전합니다.
slack.com

먼저 슬랙 사이트에 들어가서 회원가입 또는 로그인을 해준다. 구글 로그인 혹은 애플 로그인 연동이 가능하다.
이미 로그인된 상태라면 2번으로 넘어가면 된다.
2. Slack 슬랙 워크스페이스 생성
팀원들과 채팅, 파일 공유, 화상 회의를 할 수 있는 공간이다.

만약 로그인을 하게되면 이러한 화면이 나오는데 워크스페이스 생성 버튼을 눌러서 워크스페이스를 만들어주면 된다.

Slack 슬랙 워크스페이스는 무료로 만들 수 있다. 위 동의 체크를 하고 워크스페이스 생성 버튼을 누르면된다. 마케팅 소식도 받고 싶으면 체크해도 된다.

워크스페이스 이름은 원하는대로 사용하려는 의미에 맞게 적고 다음 버튼을 누르면된다. 나는 MyMacroChatBotServer 이걸로 적고 다음 버튼을 눌렀다.

그리고 워크스페이스에서 사용할 이름과 프로필 사진을 설정하고 다음 버튼을 누르면 된다.

그리고 워크스페이스에 초대할 사람의 이메일을 적고 다음 버튼을 누르거나 "이 단계 건너뛰기"를 눌러서 건너뛰면된다
나중에 다시 초대할 수 있으니 걱정하지말고 넘어가면 된다.

그리고 뭘또 적으라고 하는데 하고싶은 채널명으로 적으면된다. 나는 해당 채널에 봇을 추가하고 알림을 오게할것이므로
매크로 알림이라고 적고 다음 버튼을 눌렀다. 채널 이름은 아무거나 적어도 상관없다.

그러면 이렇게 워크스페이스가 만들어진다. 디스코드 서버랑 비슷하게 생겼는데 이제 봇을 만들고 난 다음에 워크스페이스 채널에 추가해보도록 하겠다.
3. Slack 슬랙 API 봇 만들기
Slack API로 챗봇을 만들고 권한을 설정해준다.
Slack은 생산성 플랫폼입니다
Slack은 팀과 커뮤니케이션할 수 있는 새로운 방법입니다. 이메일보다 빠르고, 더 조직적이며, 훨씬 안전합니다.
slack.com

위 API 사이트로 들어가서 우측 상단에 "Your apps" 글자를 클릭하자.

그러면 이런 화면으로 오게 되는데 위에 "Create an App" 초록색 버튼을 눌러주자

그러면 뭔가 선택하는 창이 뜨게 되는데 위에 "From scratch" 로 되어있는 곳을 선택하자.

그리고 만들려는 봇의 이름과 아까 만들었던 워크스페이스를 선택하고 "Create App" 버튼을 눌러주자 App 이름은 나중에 변경할 수 있다고 한다. 사용하려는 의미에 맞게 설정하는 것이 좋을 것 같다.

그러면 이런 화면으로 오게 되는데 여기는 기본적인 설정을 하는 곳인데 위 6개 버튼으로 바로갈 수 있다.
그러나 딱히 건드릴건 없고 채팅 권한만 설정해주면 되기 때문에 "Permissions" 버튼을 눌러주자

그리고 화면을 조금 내리면 Scopes 라는 곳이 보일텐데 여기 "Add an OAuth Scope" 버튼을 누르고 "chat" 이라고 검색을 하면 chat:write 가 나오는데 눌러주자

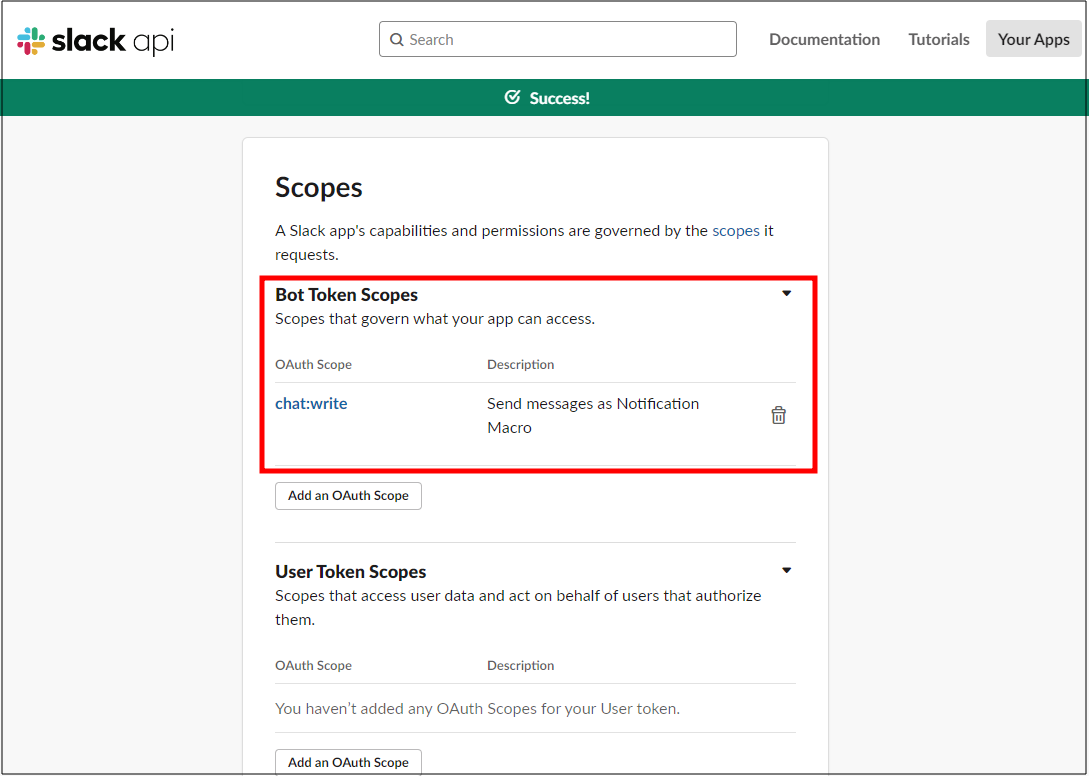
그러면 이렇게 상단에 Success 가 뜨면서 적용이 완료된다. 그리고 다시 위로 올라가자

위로 올라가면 "Install to Workspace" 버튼이 있는데 누르면 된다. 눌러보면
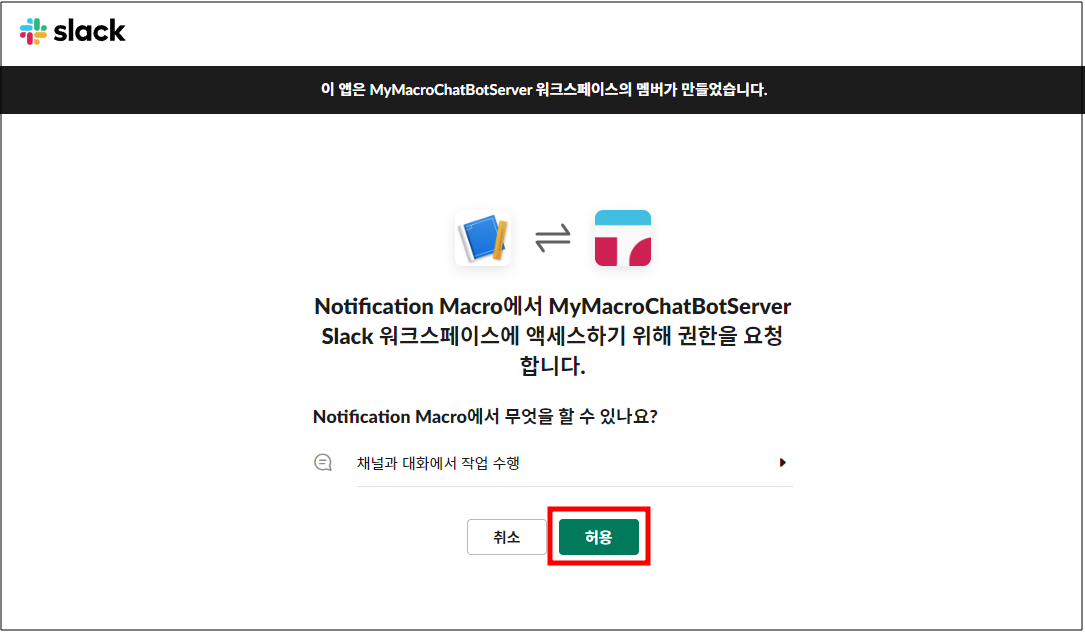
이런 창이 뜨는데 허용 버튼을 눌러주면 토큰이 생성된다.

이걸 Copy 버튼을 눌러서 복사해두면 된다.
이제 다시 우측 상단에 "Your App" 버튼을 눌러주자

그러면 이런 화면이 뜨는데 "I Agree" 버튼을 눌러주고 워크스페이스로 다시 가보자

그런다음 봇을 추가하려는 채널을 마우스 오른쪽 클릭하면 나오는 창에서 "채널 세부정보 보기" 버튼을 클릭한다.

그리고 "통합" 탭으로 가서 "앱 추가" 버튼을 눌러준다.

그러면 "워크스페이스에서" 라는 구역이 생기는데 여기에 본인이 만든 봇이 나타날것이다. 추가 버튼을 눌러서 추가해주면
봇생성과 추가가 완료된다.

이제 파이썬으로 메시지를 보내는 코드를 작성해보자
4. 파이썬 코드로 Slack 슬랙 챗봇 메시지 보내기
파이썬으로 Slack 봇 메시지를 보내는 코드를 작성한다.

원하는 파이썬 개발 환경으로 시작하면 된다. 나는 VS CODE로 하고 따로 파이썬 가상환경을 만들어서 하고 있다. 파이썬 버전은 3.10.7이다.
먼저 Slack API 를 사용하기에 앞서 slack sdk 라이브러리를 추가해준다.
pip install slack_sdk


sdk 라이브러리를 설치했으면 이제 진행하면 된다.

# Slack SDK 라이브러리 추가
from slack_sdk import WebClient
# API 인증 토큰키
myToken = '아까 복사 붙여넣었던 토큰키'
# Slack API에 접근하기 위해 토큰을 인자로 클라이언트 객체 생성
client = WebClient(token=myToken)
# 생성한 클라이언트 객체로 메시지를 전송
client.chat_postMessage(channel='매크로-알림', text='안녕하세요')
우선 해당 코드를 복사해서 붙여넣어자 그리고 아까 복사 해뒀던 토큰키를 myToken 변수에 넣고
맨 아래 코드 channel에 자신의 채널 이름을 그대로 적어주자 이 두가지를 꼭 수정하고 실행해야한다.
다 수정했으면 실행해보자

워크스페이스에 봇이 채팅을 쳤고 제대로 채팅이 들어왔다. 제대로 됐는가?
코드를 다시보자
# Slack SDK 라이브러리 추가
from slack_sdk import WebClient
이 코드는 pip 추가 했던 라이브러리를 불러오는 코드이며 꼭 있어야한다.
만약 WebClient 말고 다른 것도 쓰려면 그냥 import slack_sdk.WebClient 이렇게 해도 된다. 이럴 경우 아래 코드도 수정해줘야한다.
# API 인증 토큰키
myToken = "아까 복사 했던 API 인증 토큰키"
만들었던 봇의 인증 토큰키를 설정하는 변수이다. 이름은 아무렇게나 해도된다.
# Slack API에 접근하기 위해 토큰을 인자로 클라이언트 객체 생성
client = WebClient(token=myToken)
토큰을 매개변수로 넣어서 API에 접근하는 객체를 생성하는 코드이다. post 방식으로 채팅을 보내도 되지만 이 방식이 좀 더 코드로 작성하기에는 간단하다.
# 생성한 클라이언트 객체로 메시지를 전송
client.chat_postMessage(channel='작성한 채널 이름', text='안녕하세요')
클라이언트 객체를 이용해서 채팅을 보내는 코드이다. channel 인자에는 봇이 들어있는 채널의 이름을 적고
text 인자에는 보낼 메시지 텍스트를 넣으면 된다.
이러면 Slack API 를 이용해서 채팅 봇을 만드는 과정은 다 끝났다. 이제 파이썬 코드로 알아서 자신의 상황에 맞게 수정하면 된다. 메서드로 만들어서 매개변수를 적게 작성하는 방법도 한가지 방법일 수 있겠다.
챗봇의 사용 용도로는 알림 용도로도 쓸 수 있겠고 진짜 챗봇으로도 쓸 수 있겠는데 일단 챗봇에서 일방적으로 메시지를 보내는 방법을 알아봤다. 나같은 경우에는 일단 사이트 웹크롤링하는 코드를 여러개 돌리고 있는데 오류가 나면 다시 돌려줘야하는데 오류가났는지 매번 확인하기가 힘들기 때문에 이런 매크로 알림 챗봇이 있으면 상당히 편리하다. 다음에 시간나면 상호작용 하는 방법을 알아보고 써보도록하겠다.
* 번외
참고로 request 라이브러를 추가해서 post 방식으로 채팅을 보내는 방법도 존재한다.
# request 라이브러리 추가
import requests
# API 인증 토큰키
myToken = '챗봇 토큰 인증키'
# request post 방식으로 api 호출
requests.post("https://slack.com/api/chat.postMessage",
headers={"Authorization": "Bearer " + myToken},
data={"channel": "챗봇의 채널","text": "안녕하세요"}
)
이 방법은 slack_sdk 라이브러리를 추가하지 않고 request post 방식으로 호출하는 방법이다.
위처럼 토큰과 채널을 수정해서 보내면 된다.
headers를 저렇게 하는 이유는 저것이 Slack API의 인증 방법이라고 한다.
'프로그래밍 > Python' 카테고리의 다른 글
| 반복하지 않는 수, 중복되지 않는 수, 0부터 9까지 순열 만들기 코드 (0) | 2023.05.14 |
|---|---|
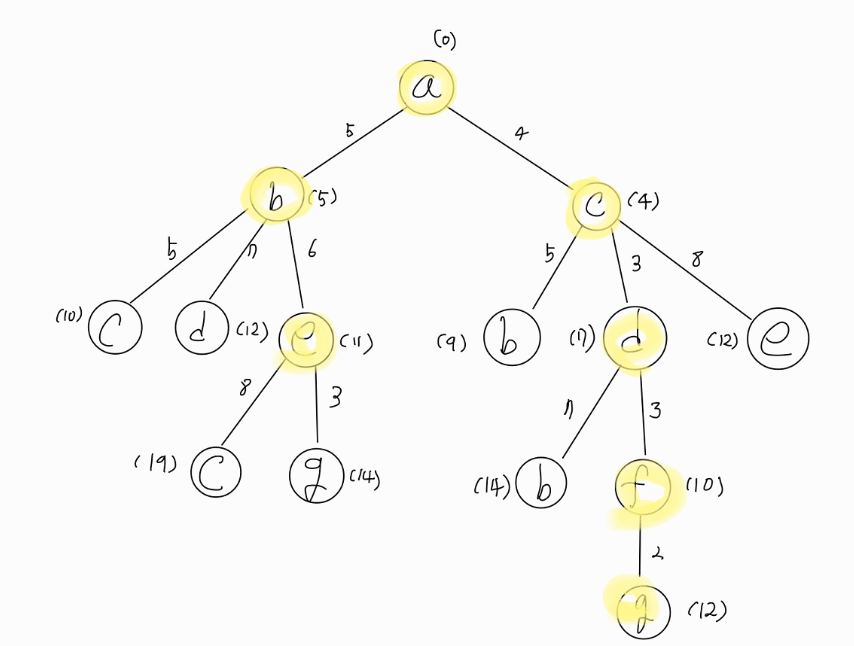
| [인공지능 학습 노트] 파이썬 UCS 구현 상태 공간 그래프에 대한 균일 비용 탐색 알고리즘 (0) | 2023.05.01 |
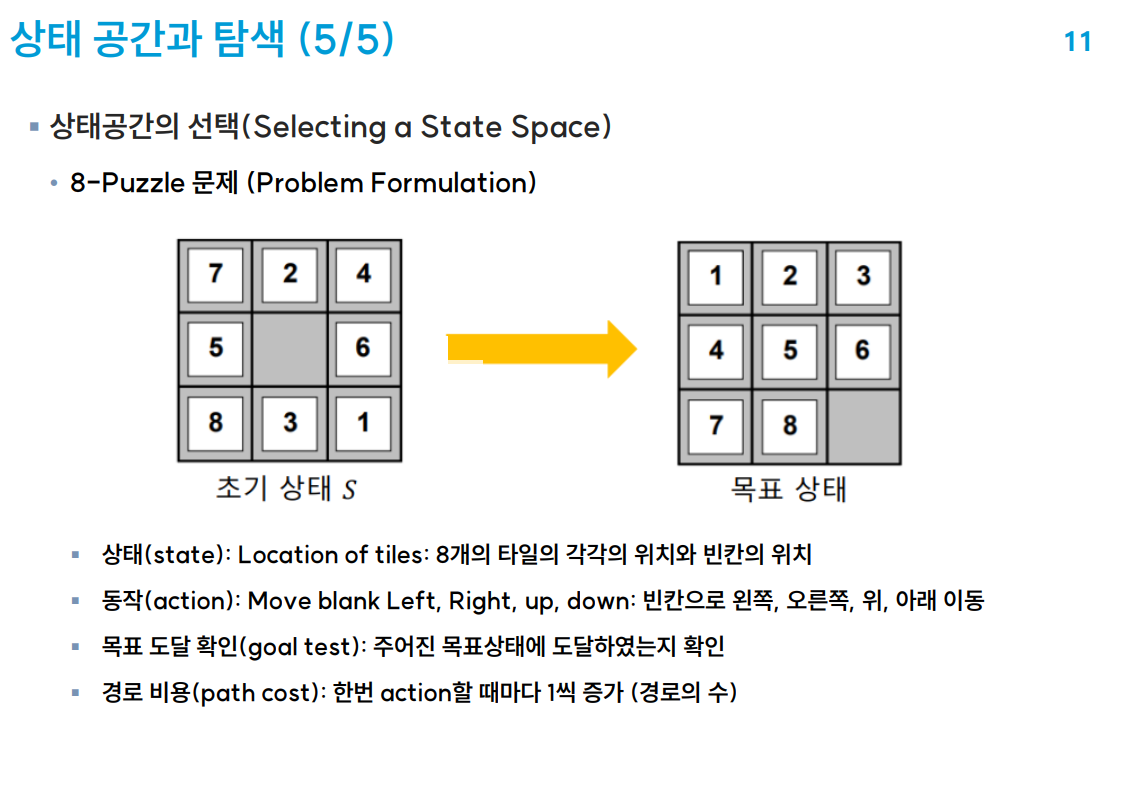
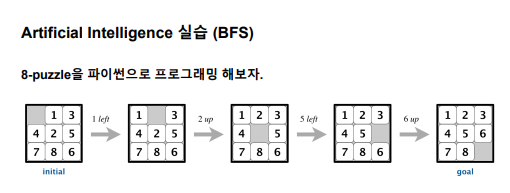
| BFS, DFS, 최선우선탐색, 휴리스틱 알고리즘, a* 알고리즘 3X3 8퍼즐 공부 (0) | 2023.03.26 |
| 파이썬 학습 노트 기초 (1) (1) | 2023.03.04 |
| 네이버 금융 주식 데이터 웹 크롤링 - 일별시세 csv파일에 저장하기 (4) | 2022.09.21 |