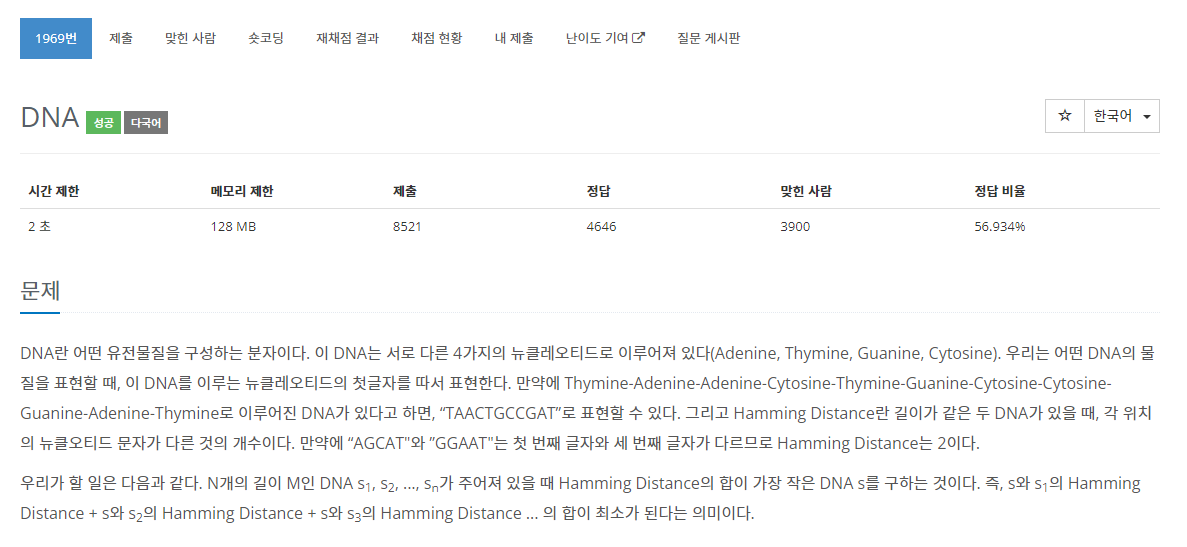
DNA란 어떤 유전물질을 구성하는 분자이다. 이 DNA는 서로 다른 4가지의 뉴클레오티드로 이루어져 있다(Adenine, Thymine, Guanine, Cytosine). 우리는 어떤 DNA의 물질을 표현할 때, 이 DNA를 이루는 뉴클레오티드의 첫글자를 따서 표현한다. 만약에 Thymine-Adenine-Adenine-Cytosine-Thymine-Guanine-Cytosine-Cytosine-Guanine-Adenine-Thymine로 이루어진 DNA가 있다고 하면, “TAACTGCCGAT”로 표현할 수 있다. 그리고 Hamming Distance란 길이가 같은 두 DNA가 있을 때, 각 위치의 뉴클오티드 문자가 다른 것의 개수이다. 만약에 “AGCAT"와 ”GGAAT"는 첫 번째 글자와 세 번째 글자가 다르므로 Hamming Distance는 2이다.
우리가 할 일은 다음과 같다. N개의 길이 M인 DNA s1, s2, ..., sn가 주어져 있을 때 Hamming Distance의 합이 가장 작은 DNA s를 구하는 것이다. 즉, s와 s1의 Hamming Distance + s와 s2의 Hamming Distance + s와 s3의 Hamming Distance ... 의 합이 최소가 된다는 의미이다.
입력
첫 줄에 DNA의 수 N과 문자열의 길이 M이 주어진다. 그리고 둘째 줄부터 N+1번째 줄까지 N개의 DNA가 주어진다. N은 1,000보다 작거나 같은 자연수이고, M은 50보다 작거나 같은 자연수이다.
출력
첫째 줄에 Hamming Distance의 합이 가장 작은 DNA 를 출력하고, 둘째 줄에는 그 Hamming Distance의 합을 출력하시오. 그러한 DNA가 여러 개 있을 때에는 사전순으로 가장 앞서는 것을 출력한다.
코드
input_count, input_length = map(int, input().split(' ')) # 첫번째 줄 입력
inputs = [list(input()) for _ in range(input_count)] # 두번쨰 줄 부터 DNA 입력 받고 리스트에 추가
inputs = list(zip(*inputs)) # 입력 받은 DNA 리스트를 전치함
answer_dna = []
answer_distance = 0
for i, v in enumerate(inputs):
inputs[i] = sorted(list(v)) # 리스트를 사전순으로 정렬함
my_dict = dict() # 키 = 뉴클레오티드 문자, 값 = 빈도수 형태로 딕셔너리를 만들거임
for j in inputs[i]:
my_dict[j] = my_dict.get(j, 0) + 1 # 빈도수 체크
min_dna = max(my_dict, key=my_dict.get) # 최다 빈도수의 뉴클레오티드의 개수
answer_dna.append(min_dna) # 정답 dna 리스트에 추가
answer_distance = answer_distance + len(inputs[i]) - inputs[i].count(min_dna) # dna 길이 - 최대 빈도수의 뉴클레오티드 개수
answer_dna = ''.join(answer_dna) # dna 리스트를 문자열로 변환
print(f'{answer_dna}\n{answer_distance}')
해결
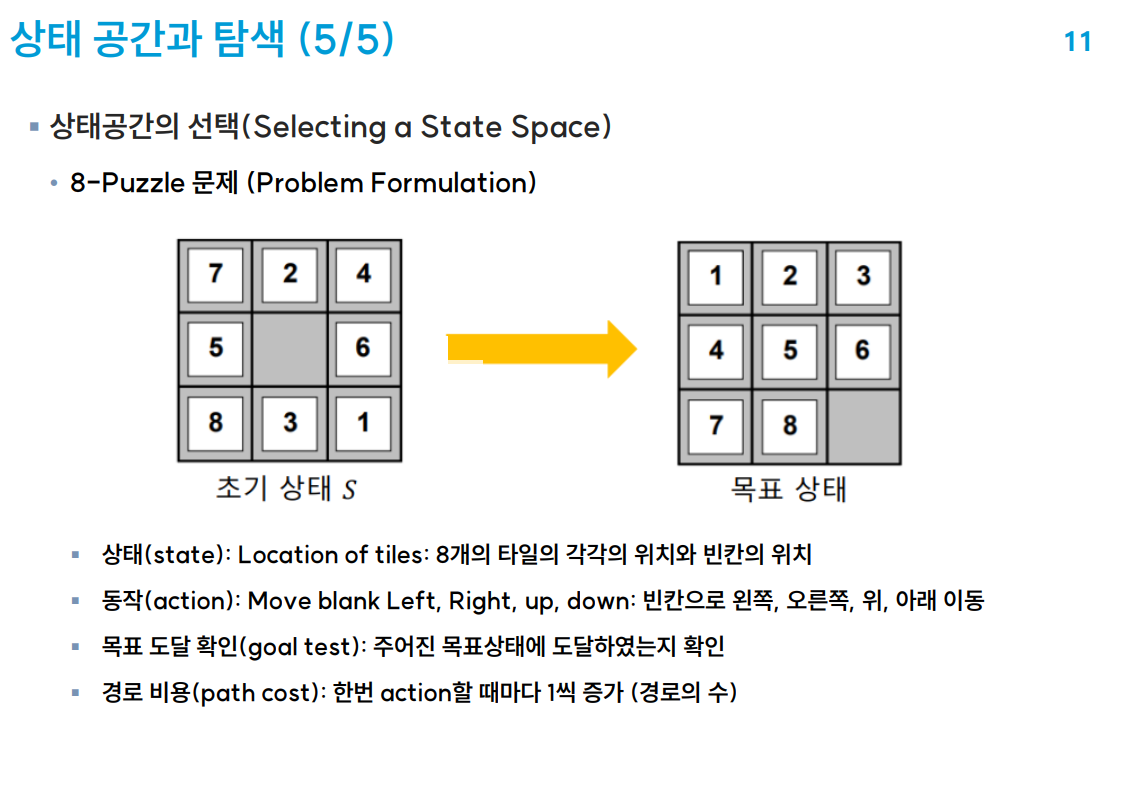
백준 문제 설명이 정말 이해하기가 어려워서 처음부터 문제를 보자면
다음과 같은 dna가 주어지면
각 열들의 행값들을 비교해서 최다 빈도수로 dna 문자열을 만들고 서로 다른 dna 즉 해밍거리를 구해야한다
세로로 AAAGA 에서 가장 많은 빈도를 가진 문자는 A 그리고 다른 문자는 G 하나 뿐이니 해밍 거리는 1
또한 세로로 AACAG 인경우 가장 많은 빈도를 가진 문자는 A 그리고 다른 문자는 C, G이니 해밍 거리는 2
게다가 해밍거리가 같은 경우 사전순으로 DNA 문자열을 만들어야 하기 때문에 정렬을 먼저 해줘야하는데
class State:
def __init__(self, board, goal, moves=0):
self.board = board
self.moves = moves
self.goal = goal
# i1과 i2를 교환하여서 새로운 상태를 반환한다.
def get_new_board(self, i1, i2, moves):
new_board = self.board[:]
new_board[i1], new_board[i2] = new_board[i2], new_board[i1]
return State(new_board, self.goal, moves)
def expand(self, moves):
result = []
i = self.board.index(0) # 숫자 0(빈칸)의 위치를 찾는다.
if not i in [0, 1, 2]: # UP 연산자
result.append(self.get_new_board(i, i - 3, moves))
if not i in [0, 3, 6]: # LEFT 연산자
result.append(self.get_new_board(i, i - 1, moves))
if not i in [2, 5, 8]: # DOWN 연산자 -> 사실 RIGHT 연산자로 추정
result.append(self.get_new_board(i, i + 1, moves))
if not i in [6, 7, 8]: # RIGHT 연산자 -> 사실 DOWN 연산자로 추정
result.append(self.get_new_board(i, i + 3, moves))
return result
# 객체를 출력할 때 사용한다.
def __str__(self):
return str(self.board[:3]) + "\n" + \
str(self.board[3:6]) + "\n" + \
str(self.board[6:]) + "\n" + \
"------------------"
def __eq__(self, other):
return self.board == other.board
if __name__ == "__main__":
puzzle = [2, 8, 3,
1, 6, 4,
7, 0, 5]
goal = [1, 2, 3,
8, 0, 4,
7, 6, 5]
# open 리스트
not_visited = [State(puzzle, goal)]
visited = []
moves = 0
while not_visited: # 스택이 빌 때까지
current = not_visited.pop(0) # 방문하려는 노드를 not_visited에서 삭제
print(current, current.moves)
if current.board == goal:
print("탐색 성공")
break
if current not in visited:
visited.append(current)
moves = current.moves + 1
for state in current.expand(moves):
if state in visited: # 이미 거쳐간 노드이면
continue # 노드를 버린다.
else:
not_visited.append(state) # 리스트 추가
DFS
class State:
def __init__(self, board, goal, moves=0):
self.board = board
self.moves = moves
self.goal = goal
# i1과 i2를 교환하여서 새로운 상태를 반환한다.
def get_new_board(self, i1, i2, moves):
new_board = self.board[:]
new_board[i1], new_board[i2] = new_board[i2], new_board[i1]
return State(new_board, self.goal, moves)
def expand(self, moves):
result = []
i = self.board.index(0) # 숫자 0(빈칸)의 위치를 찾는다.
if not i in [0, 1, 2]: # UP 연산자
result.append(self.get_new_board(i, i - 3, moves))
if not i in [0, 3, 6]: # LEFT 연산자
result.append(self.get_new_board(i, i - 1, moves))
if not i in [2, 5, 8]: # DOWN 연산자 -> 사실 RIGHT 연산자로 추정
result.append(self.get_new_board(i, i + 1, moves))
if not i in [6, 7, 8]: # RIGHT 연산자 -> 사실 DOWN 연산자로 추정
result.append(self.get_new_board(i, i + 3, moves))
return result
# 객체를 출력할 때 사용한다.
def __str__(self):
return str(self.board[:3]) + "\n" + \
str(self.board[3:6]) + "\n" + \
str(self.board[6:]) + "\n" + \
"------------------"
def __eq__(self, other):
return self.board == other.board
def __hash__(self):
return hash((tuple(self.board)))
if __name__ == "__main__":
puzzle = [2, 8, 3,
1, 6, 4,
7, 0, 5]
goal = [1, 2, 3,
8, 0, 4,
7, 6, 5]
# open 리스트
not_visited = [State(puzzle, goal)]
visited_set = set()
moves = 0
while not_visited: # 스택이 빌 때까지
current = not_visited.pop() # 방문하려는 노드를 not_visited에서 삭제
print(current, current.moves)
if current.board == goal:
print("탐색 성공")
break
if current not in visited_set:
visited_set.add(current)
moves = current.moves + 1
for state in current.expand(moves):
if state not in visited_set: # 이미 거쳐간 노드가 아니면
not_visited.append(state) # 리스트 추가
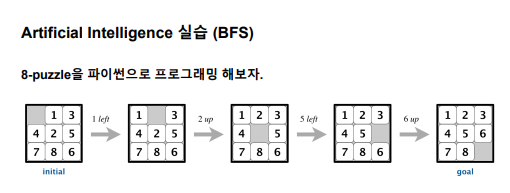
DFS는 노드간의 간선을 미리 설정해놓지 않는 무정보탐색에서는
이렇게 정말 많은 반복을 하는것같음
그래서 dfs는 set 클래스로 시간복잡도를 개선했는데
뭔 2천번 넘게 탐색을해서 저렇게 수정하는게 맞나 모르겠음
암튼 bfs도 set 클래스를 써도 되는데 코드 차이를 보라고 저렇게 해봤음
Best-First Search (그리디 알고리즘) + a* 알고리즘
class State:
def __init__(self, board, goal, moves=0):
self.board = board
self.moves = moves
self.goal = goal
# i1과 i2를 교환하여서 새로운 상태를 반환한다.
def get_new_board(self, i1, i2, moves):
new_board = self.board[:]
new_board[i1], new_board[i2] = new_board[i2], new_board[i1]
return State(new_board, self.goal, moves)
def expand(self, moves):
result = []
i = self.board.index(0) # 숫자 0(빈칸)의 위치를 찾는다.
if not i in [0, 1, 2]: # UP 연산자
result.append(self.get_new_board(i, i - 3, moves))
if not i in [0, 3, 6]: # LEFT 연산자
result.append(self.get_new_board(i, i - 1, moves))
if not i in [2, 5, 8]: # DOWN 연산자 -> 사실 RIGHT 연산자로 추정
result.append(self.get_new_board(i, i + 1, moves))
if not i in [6, 7, 8]: # RIGHT 연산자 -> 사실 DOWN 연산자로 추정
result.append(self.get_new_board(i, i + 3, moves))
return result
# 객체를 출력할 때 사용한다.
def __str__(self):
return str(self.board[:3]) + "\n" + \
str(self.board[3:6]) + "\n" + \
str(self.board[6:]) + "\n" + \
"------------------"
def __eq__(self, other):
return self.board == other.board
def __hash__(self):
return hash((tuple(self.board)))
def f(self):
return self.g() + self.h()
def g(self):
return self.moves
def h(self):
return sum([1 if self.board[i] != self.goal[i] else 0 for i in range(8)])
def __lt__(self, other):
return self.f() < other.f()
puzzle = [2, 8, 3,
1, 6, 4,
7, 0, 5]
goal = [1, 2, 3,
8, 0, 4,
7, 6, 5]
# open 리스트
not_visited = [State(puzzle, goal)]
visited_set = set()
moves = 0
while not_visited: # 스택이 빌 때까지
current = min(not_visited) # 가장 휴리스틱 값이 최적인 것을 현재 노드로 선택
not_visited.remove(current)
print(current, current.moves)
if current.board == goal:
print("탐색 성공")
break
if current not in visited_set:
visited_set.add(current)
moves = current.moves + 1
for state in current.expand(moves):
if state not in visited_set: # 이미 거쳐간 노드가 아니면
state.f_value = state.f()
not_visited.append(state) # 리스트 추가
휴리스틱 값을 퍼즐이 골의 퍼즐과 다른 상태를 h() 시작 노드에서 현재 노드까지 거리를 g() 으로 합쳐서