시험 끝나고 한 3주동안 빅데이터 공모전에 참여하기위해 열심히 달렸었다
바로 제 11회 산업통상자원부 비즈니스 아이디어 공모전!!!

처음 시작은 한~ 참 전에 시작하긴 했지만
시험 기간이 많이 겹치는 바람에 아싸리 시험 끝나고 하기로 했는데
생각보다 너무 어려웠던 것 같다
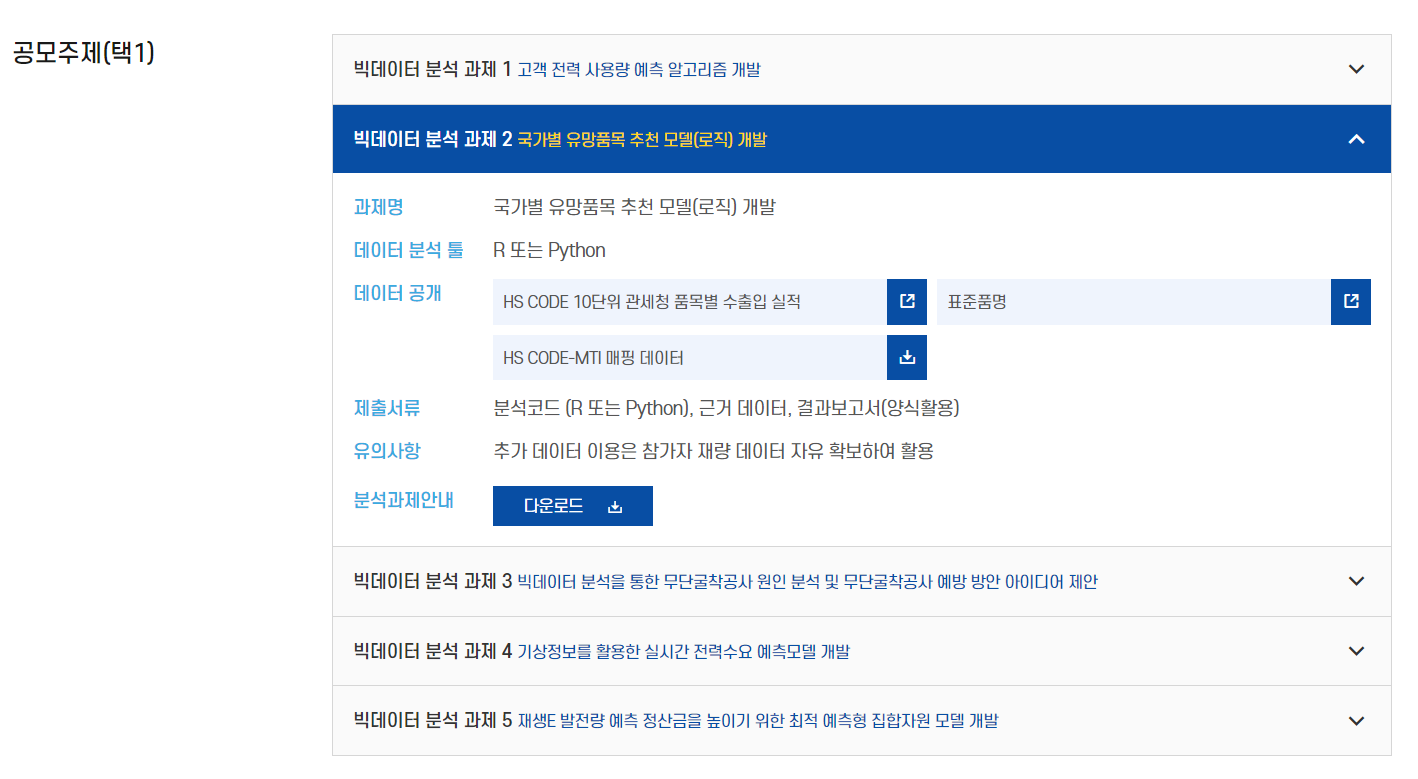
이번 공모전은 아이디어, 제품 및 서비스 개발, 빅데이터 분석
이렇게 세 부문으로 되어있었고 우리는 빅데이터 분석 부분에 참여하기로 했다
그 중에서 국가별 유망품목 추천 모델을 개발하는 것이 지정 과제인데
빅데이터라고 배워봤던적은 전에 우리 학생들끼리
빅데이터 공부 동아리를 만들어서 서로 공부한거말고는 음... 없네
빅데이터라고 딱 잘라서 뭔가 배웠다 라고는 없었기 때문에
학교 인공지능 수업 때 배운 머신러닝을 기반으로
모르는건 찾아보면서 거의 처음부터 해야했었다

엥 국가별 유망품목 추천? 그냥 그거 연도별로 수출액 딥러닝하면 끝아니뇨?
나도 그런줄 알았지... 근데 아니더라
일단 내가 처음 생각한 것은 일단 머신러닝 돌리기 전에 수출액도 중요하지만
상대 국가의 경제적, 문화적 또는 특별한 상황 등 많은 요인에 따라서 달라질 것이라고
보기 때문에 최대한 수출액 말고도 많은 데이터가 필요할 것이라고 봤다
그래서 쓸만한 데이터가 뭐가 있을지 찾아보다가
공공데이터 포털에서 관세청_품목별 국가별 수출입 실적이라는 API가 있길래 신청해서 받아 봤다
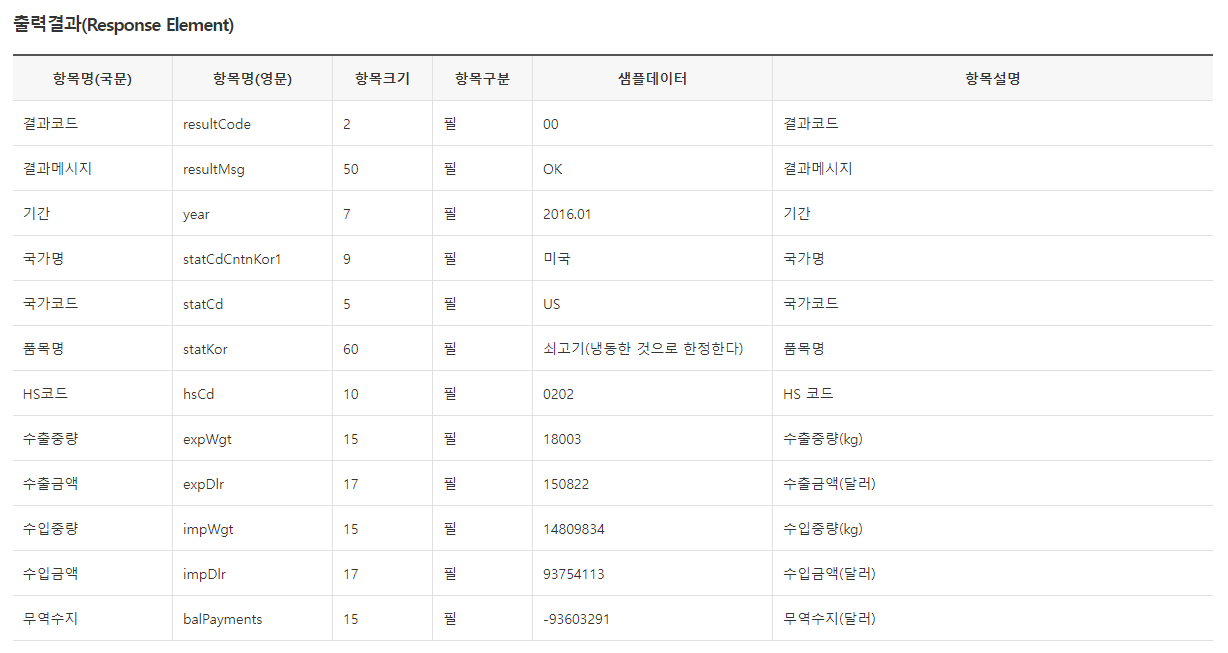
HS 코드 나오고 수출액, 수출중량, 무역수지 등등 가장 기초적으로 필요한건 나왔고
상대 국가의 경제적지표나 문화적 상황을 데이터로 어떻게 보면 좋을지 생각하다가
국가별로 인구, GDP, 실업률 등등 정보가 나오는 API도 찾을 수 있었다
근데 이런 정보는 괜찮은데 문화적인 정보를 어떻게 수치화하지 생각하다가
일단 그럼 수출액으로만 만들어보고 나중에 생각하자 하다가 그냥 수출액으로만 만들어버림...
시간이 없어서 그랬나 뭐 암튼 처음이니까
그래서 암튼 의사결정트리 모델로 대강 연도, hs, 국가코드, gdp, 실업률 이걸 X 필드로 넣고
y 필드에 수출액을 넣고 학습해봤는데 전혀 엉뚱하게 값이 나왔다
뭐가 문제인지 봤는데 일단 학습했던 데이터 값이 너무 적었고
y 값으로 넣었던 수출액이 너무 자유분방하게 넓은 범위여서 모델의 정확도가 그냥 0이 나와버린것
이걸 보완해보고자 생각했던 것은
X 필드를 연도, HS, 국가코드, 수출중량, 수출액으로 학습해서
y 필드를 수출액의 전년도 대비 증감률을 예측해보는게 어떤지 생각해봤었는데
일단 의사결정트리에 모든 국가를 다 넣어서 학습하고자 하는데
수출액이 너무 자윤분방한 값이다 보니 좀 줄여줄 필요가 있어보였던것
그럼에도 증감률도 생각보다 자유분방한 값이여서
특정구간으로 나누어버리면 어떨까했다
예를들어 증감률이 10% ~ 30% 증가하면 A 구간, 31% ~ 60% 증가하면 B구간 이렇게
이러면 나름 y값으로 들어가는 값들이 적어지지 않겠냐 생각했는데
결국엔 그냥 수출증감률로만 학습했다
암튼 수출액 데이터라도 받아야하니까 API 요청하는 코드를 짰는데
이번에 이 코드를 짜면서 나름 파이썬 프로그래밍 하는 방법에 실력이 많이 올라간 느낌이었다
예전에는 파이썬 코드를 한 파일에 대량으로 쓰는 경향이 있었는데
이번에 개인적으로 모듈화 하는데 신경을 써보자 해서
자주 쓰이는 메소드 코드는 모듈화해서 유틸 코드로 만들고
특정 기능을 수행하는 클래스도 만들어서 헬퍼 코드로 만들고
나름 코딩하는데 신경쓰면서 해서 재밌었던거같은데 문제가 하나있었다
공공데이터 포털에서 제공하는 트래픽은 일일 100제한인데 생각보다 너무 작다
교수님의 머신러닝 돌려도 생각보다 멀리 있는 데이터는 별 도움이 안된다는 나름 구원의 목소리 덕분에
2007년부터 수집하는 멍멍이 같은 행위는 피할 수 있었는데
2016녀부터 돌려도 생각보다 많아서 3일 정도 걸렸나 중간중간 트래픽을 다써서
중간에 건너뛴 데이터 복구하는데도 신경을 쓸수 밖에 없었다


그렇게 해서 뽑은 데이터들인데 뽑고 나니까 결측치라고 해야하나
수출을 안했던 날이 있는지 수출액이 0원인 경우가 생각보다 많았다
이제와서 느끼는거긴한데 이런 경우 하나하나가 생각보다 결과에 큰영향을 주더라
근데 그냥 알빠노 무지성 타조알고리즘 써버림
그래도 일단 이번에 이렇게 API 사용하면서 pandas랑 openpyxl 같은 라이브러리 사용하는데 익숙해졌다?
그리고 etree 라는 라이브러리는 xml 파싱하는 라이브러리인데 이것도 이제는 익숙해진거같다

그리고 이렇게 제네레이터 방식으로 만들었는데 제네레이터 공부도되고
솔직히 파이썬 공부했다는 방향으로는 너무 만족하는 경험이었던것같다
수출액 데이터 뽑았고 y값으로 수출액 증감률만 넣게되니 랜덤포레스트 말고 다른 모델을 찾아야했다

는 우리의 4번째 팀원 쥐피티가 알려줬는데 ARIMA 모델이라는 것이 있다고 했다
시계열 데이터를 기반으로 학습하는데 우리처럼 연도별로 데이터가 있으면
꽤 괜찮은 모델인것 같아서 바로 ARIMA 모델을 찾아봤다
그러다가 비트코인으로 알려주는 블로그를 찾을 수 있었고 그걸 보고 따라했는데
그럴려니까 데이터를 일단 연도를 분기별로 만들 필요가 있었다
연도.월 이렇게 데이터를 관리하려고 하다보니
결측치가 너무 많았던것이 문제였다 그냥 무시하려고 했는데
너무 많아서 그냥 분기별로 합쳐버리고 최대한 없는데이터가 없도록 만들고
모델에 돌려봤는데

이런식으로 데이터가 있다는걸 보여주던데
모든 데이터들이 이렇게 일관성있는 데이터가 아니라

이렇게 한순간에 겁나게 많이팔고 나머지는 거의 팔지 않는 경우가 많아서 문제였다
그래서 일단 되는거만 해보자는 마인드 노빠꾸 전진
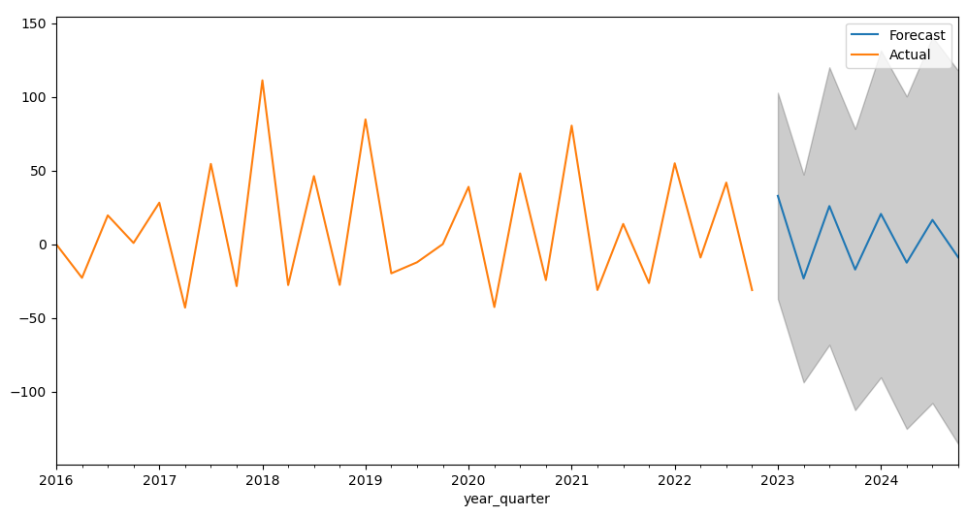
그래서 나라별로 품목별로 또 나누고 해서 VN 이란 나라에서 15 HS 코드가 2016 년부터 2022년까지
해당 수출 추세를 보였는데 2023년부터 어떻게 될지 예측해본 결과이다

이번에는 같은 데이터로 2016년부터 2020년까지만 학습하고 21년부터 예측을 해봤는데
실제 데이터랑 비교를 해보니 증감률은 완전 정확하지는 않지만
증감폭은 어느정도 맞긴하지만 놀라운건 +, - 인지는 대략 맞아떨어진다!!

그래서 아무튼 진행시킴 완전 엉터리는 아니라는거
이정도로 하고 결과물이랑 코드 그리고 보고서 작성해서 제출했는데
국내 천재라는 사람들이 얼마나 많은데 생초짜가 처음 참여하는 공모전이라
한 99.8% 는 참여에 의의를 두고 0.2% 정도는 뭐라도 하자에 의의를 두는게 맞는거같다
시간이 좀 있었더라면 잘할수있었을란지는 모르겠지만 이번 공모전을 참여하면서 느낀점은 확실히 알거같다
일단 이번 공모전 참여하면서 얻은것은 첫번째 파이썬 프로그래밍 실력이 확실히 늘었다
API 요청하는 코드를 짜면서 request, 태그파싱, 모듈화, 예외처리, 이터레이터, pandas, openpyxl 등등
학교에선 배우지 못했던 파이썬 문법과 응용방법에 대해 생각보다 잘 알게 되었다.
그리고 두번째 인공지능에게 학습하기 전에 데이터 전처리가 정말 중요하다는 것을 알게되었다
모델이 생각보다 똑똑한데 생각보다 멍청해서 결측치에 영향을 쉽게 받는 다는 것이 놀라웠다
마지막으로 랜덤포레스트와 아리마 모델을 공부하면서 랜덤포레스트는 회귀, 분류가 가능하지만
값이 너무 자유분방하면 안된다는 것을 알게 되었고 아리마 모델은 결측치에 정말 쉽게
영향을 받아 학습된다는 것을 알게 되었다
다음에 공모전있으면 시간나면 더 공부해서 참여하면 좋겠다
import pandas as pd
from matplotlib import pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
# CSV 파일을 DataFrame으로 읽어옵니다.
data = pd.read_csv('VN.csv')
# 'year'를 날짜 형식으로 변환하고 이를 인덱스로 설정합니다.
data['year'] = pd.to_datetime(data['year'], format='%Y-%m') # format 수정
data.set_index('year', inplace=True)
# 시계열 데이터 추출
series = data['value']
# ARIMA 모델 생성과 학습
model = ARIMA(series, order=(1, 1, 1)) # ARIMA 모델의 order를 설정합니다.
model_fit = model.fit()
# 모델 요약 정보 출력
print(model_fit.summary())
# 모델 예측 결과 그래프 그리기
fig, ax = plt.subplots(figsize=(12, 6))
# 예측 범위 설정
start_date = pd.to_datetime('2021-01-01')
end_date = pd.to_datetime('2024-12-01')
# 모델 예측
pred = model_fit.get_prediction(start=start_date, end=end_date)
# 예측된 평균 값 그래프 그리기
pred.predicted_mean.plot(ax=ax, label='Forecast')
# 신뢰구간 표시
ax.fill_between(pred.conf_int().index,
pred.conf_int().iloc[:, 0],
pred.conf_int().iloc[:, 1], color='k', alpha=.2)
# 원본 데이터 그래프 그리기
series.plot(ax=ax, label='Actual')
plt.legend()
plt.show()
# 한 단계 예측
fore = model_fit.forecast(steps=5)
print(fore)
import pandas as pd
from matplotlib import pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
# CSV 파일을 DataFrame으로 읽어옵니다.
file_name = r'VN_15_ratio.csv'
data = pd.read_csv(r'\ASD\incremental additional data' + f'\{file_name}')
print(data)
# 'year_quarter'를 Period 형식으로 변환하고 이를 인덱스로 설정합니다.
data['year_quarter'] = data['year_quarter'].apply(lambda x: pd.Period(x, freq='Q')) # 수정된 부분
data.set_index('year_quarter', inplace=True)
print(data.index)
# 시계열 데이터 추출
data = data[data.index < '2021Q1']
series = data['expDlr_change']
# ARIMA 모델 생성과 학습
model = ARIMA(series, order=(1, 1, 0)) # ARIMA 모델의 order를 수정했습니다.
model_fit = model.fit()
# 모델 요약 정보 출력
print(model_fit.summary())
# 모델 예측 결과 그래프 그리기
fig, ax = plt.subplots(figsize=(12, 6))
# 예측 범위 설정
start_period = pd.Period('2021Q1') # 원본 데이터의 마지막 시점 다음으로 설정
end_period = pd.Period('2024Q4') # 예측 종료 시점은 2024Q4로 설정
# 모델 예측
pred = model_fit.get_prediction(start=start_period, end=end_period)
# 예측된 평균 값 그래프 그리기
pred.predicted_mean.plot(ax=ax, label='Forecast')
# 신뢰구간 표시
ax.fill_between(pred.conf_int().index.to_timestamp(),
pred.conf_int().iloc[:, 0],
pred.conf_int().iloc[:, 1], color='k', alpha=.2)
# 원본 데이터 그래프 그리기
series.plot(ax=ax, label='Actual')
plt.legend()
plt.show()
# 한 단계 예측
fore = model_fit.forecast(steps=5)
print(fore)
'정리 전 게시글 > 개발 관련' 카테고리의 다른 글
| 시각장애인을 위한 거리 측정 보행 보조 안내 프로젝트 회고 - 3학년 캡스톤 디자인 (1) | 2023.12.24 |
|---|---|
| 2023년 공개 SW 개발자 대회 참여 회고 (우수작 선정... 😥) (1) | 2023.12.24 |
| 2023년 경상국립대 5월 동아리축제 이카루스 부스 활동 (1) | 2023.05.18 |
| 2023년 USG 스마트제조ICT 코딩테스트 경진대회 참여 후기 (0) | 2023.05.01 |
| 2023년 USG 스마트제조ICT 전공 OT, 진로설계 캠프 후기 (0) | 2023.02.22 |